

Designing Data-Intensive Applications - Chapter 1 (Reliable, Scalable, and Maintainable Applications)


What is a data-intensive application?
Many applications today are data-intensive, as opposed to compute-intensive. Raw CPU power is rarely a limiting factor for these applications, bigger problems are usually the amount of data, the complexity of data, and the speed at which it is changing.
A data-intensive application is typically built from standard building blocks that provide the commonly needed functionality. For example, many applications need to:
- Store data so that they, or another application, can find it again later (databases)
- Remember the result of an expensive operation, to speed up reads (caches)
- Allow users to search data by keyword or filter it in various ways (search indexes)
- Send a message to another process, to be handled asynchronously (stream processing, message queue)
- Periodically crunch a large amount of accumulated data (batch processing)
If that sounds painfully obvious, that’s just because these data systems are such a successful abstraction as when building an application, most engineers may know some of these tools.
But the reality is not that simple. There are many database systems with different characteristics because different applications have different requirements. There are various approaches to caching, several ways of building search indexes, and so on. When building an application, we still need to figure out which tools and which approaches are the most appropriate for the task at hand. And it can be hard to combine tools when you need to do something that a single tool cannot do alone.
Thinking About Data Systems
We typically think of databases, queues, caches, etc. as being very different categories of tools. Although a database and a message queue have some superficial similarities —both store data for some time— they have very different access patterns, which means different performance characteristics, and thus very different implementations.
So why should we lump them all together under an umbrella term like data systems?
Many new tools for data storage and processing have emerged in recent years. They are optimized for a variety of different use cases, and they no longer neatly fit into traditional categories [1]. For example, there are datastores that are also used as message queues (Redis), and there are message queues with database-like durability guarantees (Apache Kafka). The boundaries between the categories are becoming blurred.
Secondly, increasingly many applications now have such demanding or wide-ranging requirements that a single tool can no longer meet all of its data processing and storage needs. Instead, the work is broken down into tasks that can be performed efficiently on a single tool, and those different tools are stitched together using application code.
For example, if you have an application-managed caching layer (using Redis), or a full-text search server (such as Elasticsearch) separate from your main database, it is normally the application code’s responsibility to keep those caches and indexes in sync with the main database.
The following diagram shows an example of how the application code can stitch those data systems together.
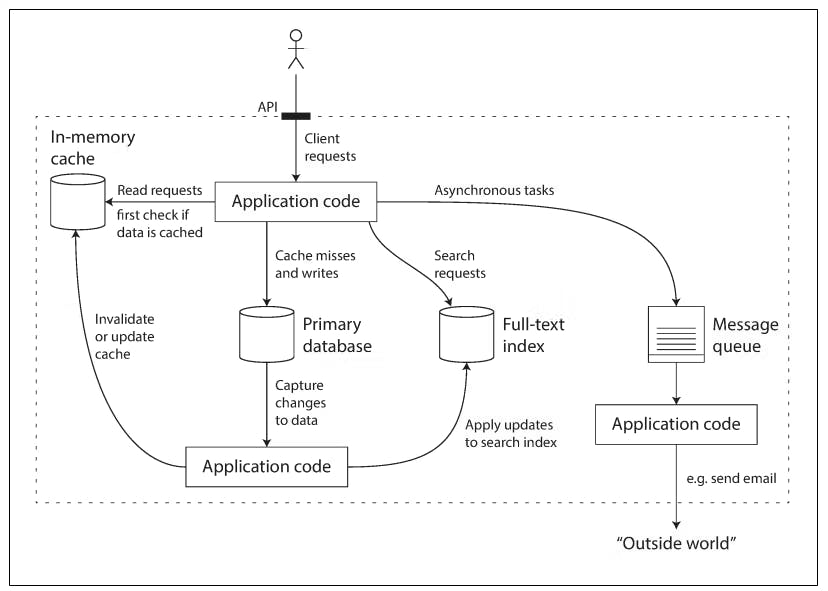
If you are designing a data system or service, a lot of tricky questions arise.
- How do you ensure that the data remains correct and complete, even when things go wrong internally?
- How do you provide consistently good performance to clients, even when parts of your system are degraded?
- How do you scale to handle an increase in load?
- What does a good API for the service look like?
There are many factors that may influence the design of a data system, including the skills and experience of the people involved, legacy system dependencies,.. etc. The book focuses on three concerns that are important in most software systems:
- Reliability
- Scalability
- Maintainability
Reliability
It means the system continues to work correctly, even when things go wrong.
We can think of work correctly as:
- The application performs the function that the user expected.
- It can tolerate the user making mistakes or using the software in unexpected ways.
- Its performance is good enough for the required use case, under the expected load and data volume.
- The system prevents any unauthorized access and abuse.
The things that can go wrong are called faults, and systems that anticipate faults and can cope with them are called fault-tolerant or resilient
the fault-tolerant term is slightly misleading thus it suggests that we could make a system tolerant of every possible kind of fault, which in reality is not feasible. So it only makes sense to talk about tolerating certain types of faults.
Note that a fault is not the same as a failure. A fault is usually defined as one component of the system deviating from its spec, whereas a failure is when the system as a whole stops providing the required service to the user.
It is impossible to reduce the probability of a fault to zero; therefore it is usually best to design fault-tolerance mechanisms that prevent faults from causing failures.
There are 3 main sources of faults that can affect a system, namely:
Hardware Faults
All of our software systems run on hardware and supporting infrastructure of power grids and communication cables that are susceptible to faults causing our software to fault as well. A very common example of this is hard disk failures in data centers, for example, hard disks are reported as having a mean time to failure (MTTF) of about 10 to 50 years. Thus, on a storage cluster with 10,000 disks, we should expect on average one disk to die per day.
Those types of faults are usually handled by trying to minimize the downtime of fixing those hardware faults (usually by replacing the faulty component). This is usually done via redundancy, for example, using RAID hard disks, having standby replicas that can take over the job of the faulty component until it's swapped for a functioning one, etc.
So other systems have an interesting take on solving hardware failures, like for example, the cloud provider AWS. Instead of shedding focus on being tolerant of hardware failures, they shed more focus on building systems that can tolerate the loss of entire machines or even entire availability zones (an AWS term of a group of data centers).
This concept is even extended to not only handle unexpected machine loss but to also make operations easier. For example, intentionally taking a machine out of circulation to be fixed/patched/updated can be modeled as if that machine was lost and the software can deal with that loss thus making operations easier and minimizing downtime and maintenance windows.
Software Errors
Another type of fault that can cause a system to fail is, of course, software errors. Examples include:
- A software bug that causes every instance of an application server to crash when given a particular bad input. For example, consider the leap second on June 30, 2012, that caused many applications to hang simultaneously due to a bug in the Linux kernel
- A runaway process that uses up some shared resource—CPU time, memory, disk space, or network bandwidth.
- A service that the system depends on that slows down, becomes unresponsive, or starts returning corrupted responses.
- Cascading failures, where a small fault in one component triggers a fault in another component, which in turn triggers further faults
There is no quick solution to the problem of systematic faults in software. Lots of small things can help: carefully thinking about assumptions and interactions in the system; thorough testing; process isolation; allowing processes to crash and restart; measuring, monitoring, and analyzing system behavior in production.
Human Errors
Humans make mistakes and that's an inevitable fact. One study of large internet services found that configuration errors by operators were the leading cause of outages, whereas hardware faults (servers or networks) played a role in only 10–25% of outages.
There are however a lot we can do to make systems reliable even when a human error happens such as:
- Design systems in a way that minimizes opportunities for error. For example, well-designed abstractions, APIs.
- Decouple the places where people make the most mistakes from the places where they can cause failures. In particular, provide fully featured non-production sandbox environments where people can explore and experiment safely, using real data, without affecting real users.
- Test thoroughly at all levels, from unit tests to whole-system integration tests and manual tests. Automated testing is widely used, well understood, and especially valuable for covering corner cases that rarely arise in normal operation.
- Allow quick and easy recovery from human errors, to minimize the impact in the case of a failure. For example, make it fast to roll back configuration changes, roll out new code gradually (so that any unexpected bugs affect only a small subset of users), and provide tools to recompute data (in case it turns out that the old computation was incorrect).
- Set up detailed and clear monitoring, such as performance metrics and error rates. In other engineering disciplines, this is referred to as telemetry. (Once a rocket has left the ground, telemetry is essential for tracking what is happening, and for understanding failures [14].) Monitoring can show us early warning signals and allow us to check whether any assumptions or constraints are being violated. When a problem occurs, metrics can be invaluable in diagnosing the issue.
- Implement good management practices and training—a complex and important aspect, and beyond the scope of this book.